Poster, Cosyne 2022
Poster, Cosyne 2022
Abstract
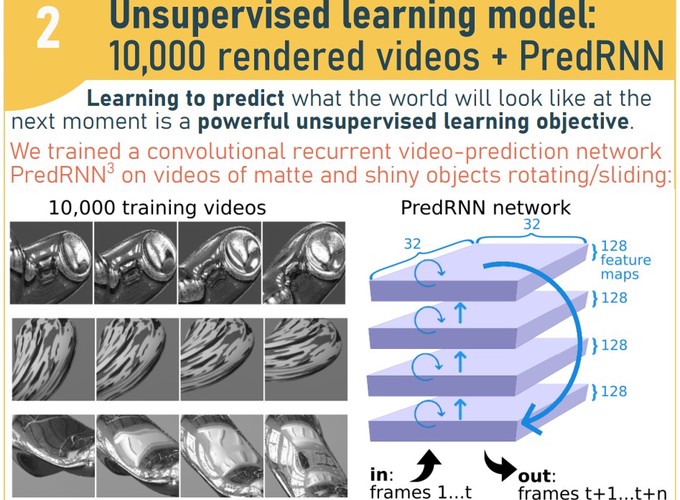
Visually understanding the world requires us to interpret surface properties like shape, depth, and reflectance from retinal images—with little or no access to the ground truth about these properties from which to learn. Previous work showed that perception and misperception of surface reflectance in static images is well predicted by unsupervised learning in a feedforward PixelVAE network. Here we extend into the temporal domain, testing whether learning-by-prediction in a recurrent network discovers the properties of moving surfaces to which humans are sensitive. We rendered 10,000 close-up videos of objects moving with random trajectories, speed, illumination, and reflectance. We trained a four-layer recurrent ‘PredRNN’ network to predict the pixels of the next frame in each video. The network could extrapolate up to ten frames beyond its input data with high quality. Investigating internal representations, we found that over time scenes became strongly clustered according to whether they depicted a matte or mirror-like surface. Material, shape, illumination, texture, and velocity could all be decoded from the network’s internal representations using linear classifiers, with accuracy peaking in different layers and time points for different properties. As well as this population-level information, we found strong selectivity in many individual units for specific properties (e.g. a preference for matte rather than mirrored surfaces). Both static and motion cues contribute to material perception in humans. To compare human and model sensitivity to each cue type, we created test videos depicting either static or moving reflective objects, or moving versions in which reflections were ‘stuck’ to the surface. All had identical static material cues, but differed in motion cues. Model-predicted material agreed with human judgements (N=16) of the relative reflectance of stimuli. Results suggest predictive learning discovers human-relevant material cues, and provides a framework for understanding how brains learn rich scene representations without ground-truth world information.