Invited talk: Learning to See Stuff: Unsupervised Neural Networks Learn Idiosyncrasies of Human Perception
Invited talk: Learning to See Stuff: Unsupervised Neural Networks Learn Idiosyncrasies of Human Perception
Abstract
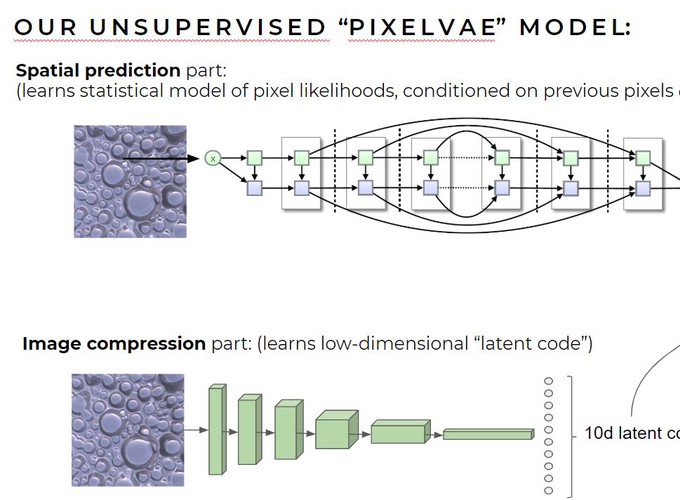
How do we see the outside world? Materials with complex appearances, like a glossy bumpy surface seen under natural lighting, pose particular challenges for classical ‘inverse optics’ theories of perception, which assume the brain’s goal is to estimate physical quantities like the reflectance of surfaces. Nor is their perception easily explained by supervised deep learning models, which would require large datasets labelled with the true properties of physical scenes. However, recent advances in unsupervised deep learning provide a framework for explaining how representations could more plausibly emerge by learning to encode and predict visual inputs as efficiently and accurately as possible. I will present two projects in which unsupervised deep networks learn about simple simulated worlds from datasets of images generated from those worlds using physically-based rendering. In the first project, a PixelVAE network uses the unsupervised objectives of image compression and spatial prediction to learn about surfaces with different shapes, materials, and illuminations. In the second project, a PredNet network uses temporal prediction to learn from videos about objects with different shapes, motions, positions and materials. In both cases, the latent representations within the trained networks contain rich information about the underlying factors in the generating worlds, implying that unsupervised visual systems can automatically discover how to disentangle distal causal factors. Most remarkably, the representations of ‘world factors’ within the networks display certain idiosyncrasies of human perception. The PixelVAE model predicts human-perceived glossiness of novel surfaces better than ground-truth material gloss, and better than a deep network model directly supervised on gloss estimation. It predicts a known illusion in material perception, in which the perceived gloss of a constant material varies with surface shape, and is able to predict specific patterns of human errors for specific images. I suggest that many visual ‘illusions,’ such as failures of constancy, may be signatures of the way brains learn to see, by efficiently encoding and predicting proximal image data, and that unsupervised deep learning may thus provide a coherent explanation of both failures and successes in perception.